Continuous delivery for Alfresco
Alfresco upgrades can range from the very simple and quick to those requiring days or weeks of downtime. Obviously weeks of downtime is unacceptable and this can be one of the barriers keeping customers on older versions of Alfresco.
I’ve now worked on several finely crafted upgrades of alfresco applications, the most recent of which included an application code change, new infrastructure and a major alfresco version upgrade. It required a detailed plan which was first run on a couple of test environments, followed by an update to the live system over a weekend. In this particular case there was a patch that initially took a couple of days to run, which was too long. I rewrote that patch to get it to work in a couple of hours which was acceptable and successful, but there has to be a better way.
Happily the introduction of cloud environments like Amazon Web Services and tools such as Terraform and Ansible allows us to “spin up” new environments on demand, and then throw them away once they are no longer required. As well as not paying for environments you are not using, this also has the benefit of having the environments fully under control; as soon as you start allowing manual configuration then inconsistencies and errors inevitably creep in. It’s typical to have multiple environments such as dev, integration, pre-prod and live; so far I’ve seen these managed as long lived permanent environments, but it is possible to spin up an environment, run a set of tests and then destroy it; we have been doing that with Maven based Selenium and jUnit tests run by Jenkins and Bamboo for years.
So why not use the same techniques for releasing code all the way to production? What is important is the persistence of the data, not the configuration of the server running the code which can be re-generated at will. I’ve seen a blog discussing the need for so called Phoenix servers which are destroyed and then re-created at will (rising from the ashes) that rings true for me when working with Alfresco. I’ve already seen too many subtle configuration inconsistencies causing problems in the short time I’ve been with Zaizi.
Blue-green deployment is a strategy for deploying new versions of software. It relies on maintaining two separate production-capable environments to minimize or eliminate the downtime when releasing an upgrade. A new instance is brought to readiness with the new version of software and then switched to replace the formerly live environment.
Another related strategy is the so called canary release where a separate production-capable environment is brought to readiness and a few users switched to the new release. Should those users be O.K. then more users are switched until the old release is unused.
While the content store within alfresco is well behaved with regard to update (as long as you turn off deletion while you are in the process of upgrading) the alfresco data model and alfresco infrastructure can be more of a problem.
Multiple Alfresco Nodes Sharing A Single Database.
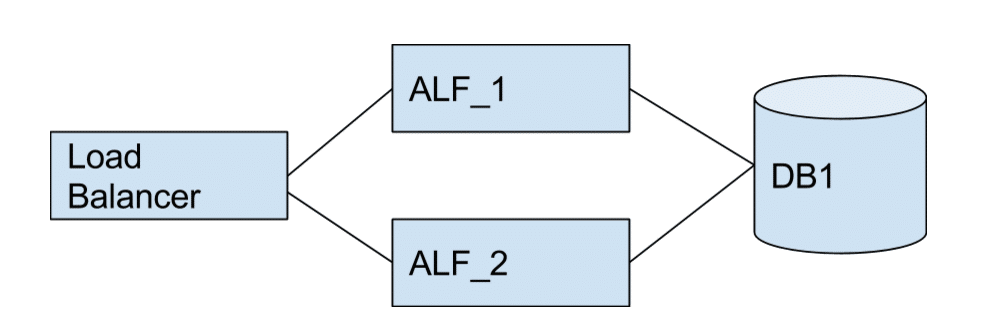
Multiple alfresco nodes sharing a single database is perhaps the easiest first step. A new node ALF_2 is brought up, and the old node ALF_1 removed from the load balancer and eventually retired when it is no longer in use. For perhaps the majority of changes this is ok. However there are limitations with incompatible changes which will be discussed later.
Its also worth noting that its necessary to test this deployment process before getting to production so any incompatible updates can be flagged early. So ideally we use the same deployment approach for our development, integration and pre-production environments rather than doing something special and untested for production.
Parallel Alfresco Instances
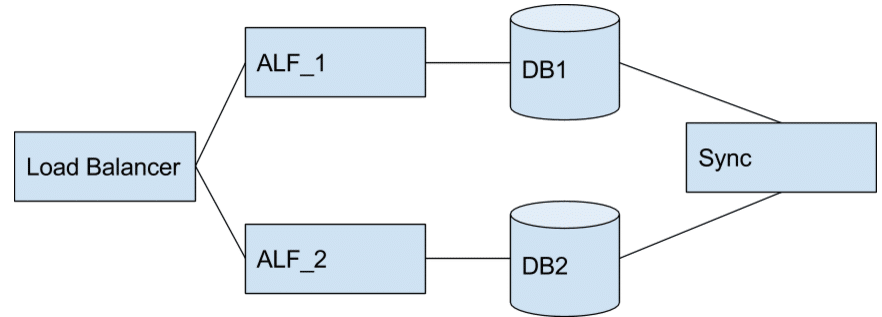
Parallel alfresco instances, each with their own database and a synchronization process for synchronization between the two for the delta while the systems are running in parallel.
The parallel approach is more complicated but can deal with more upgrade scenarios and has a cleaner roll-back. But on the downside requires an extra and potentially complex component, the synchronizer, which may also need to convert between different versions of a data model. It may also have data consistency problems, for example if there are parallel requests to lock a node from ALF_1 and ALF_2 which instance wins?
A way of side-stepping this issue could be to make ALF-1 read only while ALF-2 is brought up and tested. That may work for some business cases, in particular it may be better to be able to give some read only access to the existing system rather than no access at all.
This way of working has also been used by many clients to re-build the alfresco full text indexes. A new index is built in parallel and once complete is used to replace the old index.
So let’s consider the shared database approach in more detail. Probably the majority of simple changes can be easily deployed this way, for example the addition of a new web-script, a bug fix or the addition of a new aspect or optional property. These sorts of changes can happily co-exist with old versions.
Then there are alfresco patches which may be required. From time to time Alfresco will need to change the database schema. The Alfresco support policy is to restrict incompatible schema changes to major Alfresco releases (and we hope that Alfresco itself will minimize changes because it has to manage its own cloud environment) it may be incompatible with the old schema. In these cases of a major incompatibility a single database deployment will require a stop/start deployment.
Application patches run on update between different versions of alfresco. Most are not a problem, for example if they simply add a new model or change some configuration data. However there are scripts that need to manipulate the alfresco metadata or model. There are occasionally scripts that need to process millions of documents and these take a long time. Long running patches may be mitigated at code level by techniques like lazy conversion or running the patch asynchronously or running the conversion through the batch processor. But sometimes, thankfully rarely, it is not possible to put a “round peg in a square hole.”
Data Model Changes
In a similar way that java classes are compatible with older versions, there are changes that can co-exist with an old version of the model and some changes which can’t. For example addition of a new mandatory property or a new more restrictive constraint will be incompatible with the old version. It is possible to mitigate some of these problems at code level, for example by patching data first or applying the update with an intermediate deployment which first provides a default property value and then a second deployment makes that property mandatory. Or in the case of a constraint it may be acceptable for the new model to introduce stricter validation immediately. I suspect that these changes will need to be considered on a case by case basis.
Alfresco nodes contain a shared in-memory cache. For most of the time the structure of this cached data does not change but major releases of alfresco can and do change the structure or introduce new caches. For these releases it may be necessary to break the cluster so green and blue are independent. That may also introduce other temporary problems but hopefully this is a rare occurrence. This becomes rather more a problem if we consider parallel blue green deployment where the caches may become stale as data is injected by the synchronizer.
Rules are persisted in Alfresco so a new rule will immediately affect the old instance as well as the new. This is probably not going to be a problem but does indicate a weakness of the shared database approach. Should the deployment fail then the roll-back is not clean. There are also a number of similar alfresco based configuration settings such as templates and webscripts in the alfresco data dictionary. However for Alfresco deployment we are not really using blue green deployment to get a clean roll back, that would be tested on an earlier deployment which we would simply throw away after use, we are using it to minimize downtime.
The final part of alfresco models are behaviours and policies which allow you to tie application code to the events of a data model. If blue and green have inconsistent policies then it can cause problems similar to adding a new constraint. The difference may be mitigated by code but again this may be impossible to put the “round peg in a square hole.” Thankfully I suspect that most cases are fairly simple.
The Alfresco Enterprise License is specific to a particular version of alfresco so with a shared database blue / green deployment that includes a major alfresco version upgrade then there is a chance that the old nodes will lock as read only when the license is validated, or worse the new nodes will fight with the old nodes and the entire system randomly switches between read/only and read/write. This may restrict the use of blue/green to minor alfresco version update only. But it may also be possible to do a major update if the time is kept short. Really the Alfresco License code needs to be changed to enable these sorts of deployments.
Alfresco Modules (AMPS and Simple Jar Modules) have a module version number which is validated on repository start-up and Alfresco can refuse to start if there is a missing module or a mismatched version number. One simple work-around to this is simply to keep the existing alfresco nodes running and not to try to start a node with the old configuration while the blue / green deployment is in progress. Hopefully there will be better support for re-deploying alfresco modules at runtime soon from Alfresco, I’ve seen and used a few early prototype implementations.
Current Position At Zaizi
We have an ongoing need to update Alfresco Instances for many different clients. And we also have a set of tools that we are already using to help with deployment on cloud environments. So it is a natural progression to want to be able to reduce the risk of upgrade and decrease the downtime.
To put a figure on things, I’d estimate that it’s achievable to continuously deliver 95% of alfresco changes. As ever, there is a lot of effort required to fix those odd and difficult cases that will remain but that should not stop us from trying to improve.
We have many different client requirements and not all environments are the same, so I doubt that we will ever reach a single solution for continuous delivery of Alfresco, just as we already need to use a basket of tools. Some Alfresco instances are hosted on AWS where I’d like us to move to using a ‘Phoenix’ Blue/Green pattern. Other cloud or hosted environments are less amenable to scripting so that’s probably going to need a slightly different approach with longer running ‘Snowflake’ instances.
Related content
-

Key takeouts from Alfresco Day
Published on: 27 September, 2019 -

Alfresco DevCon 2019: Alfresco listening and moving forwards
Published on: 18 February, 2019 -

Alfresco DevCon 2019: A look at Alfresco’s products
Published on: 18 February, 2019 -

Alfresco DevCon 2019: Documenting the future
Published on: 18 February, 2019